
Ever wondered how your smartphone can effortlessly recognize faces in photos or how self-driving cars navigate through traffic? The magic behind these technologies is powered by Convolutional Neural Networks (CNNs). In this guide, we’ll take you on an exciting journey into the world of CNNs, uncovering the secrets behind what a Convolutional Neural Network is and why it’s revolutionizing the way machines understand visual data.
We’ll dive into the nuts and bolts of CNNs, exploring their history and key components like convolutional layers, activation functions, and pooling layers. Discover how these elements work together to make sense of complex images and see how CNNs are transforming industries and everyday technology. Whether you’re curious about the basics or eager for a deeper dive, this article will provide an engaging and thorough look at the powerful world of CNNs.
What is a Convolutional Neural Network (CNN)?
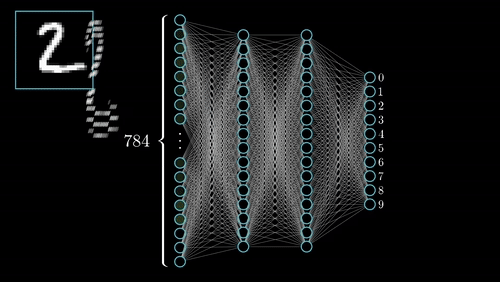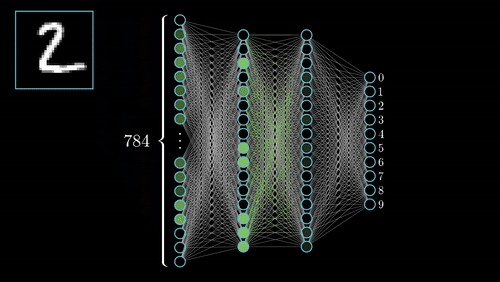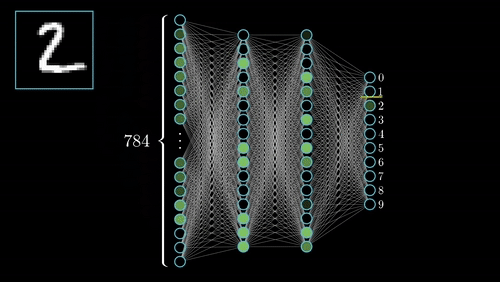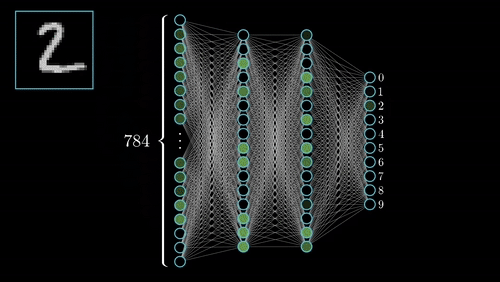
Definition of CNN
Convolutional Neural Networks (CNNs) are a powerful type of artificial intelligence designed to analyze visual data, like images. They are a key technology behind many modern applications, such as facial recognition in photos and autonomous vehicles navigating roads.
Key Features of CNNs:
- Specialized for Images: CNNs are particularly good at working with grid-like data, such as the pixels in an image. They can detect patterns like edges and textures, which helps in identifying objects.
- Layered Learning: They learn features in a layered fashion. Early layers might recognize simple patterns like edges, while deeper layers combine these patterns to identify more complex shapes and objects.
- Efficient Structure: Unlike traditional neural networks, CNNs use local connections and shared weights, making them more efficient in handling large amounts of data.
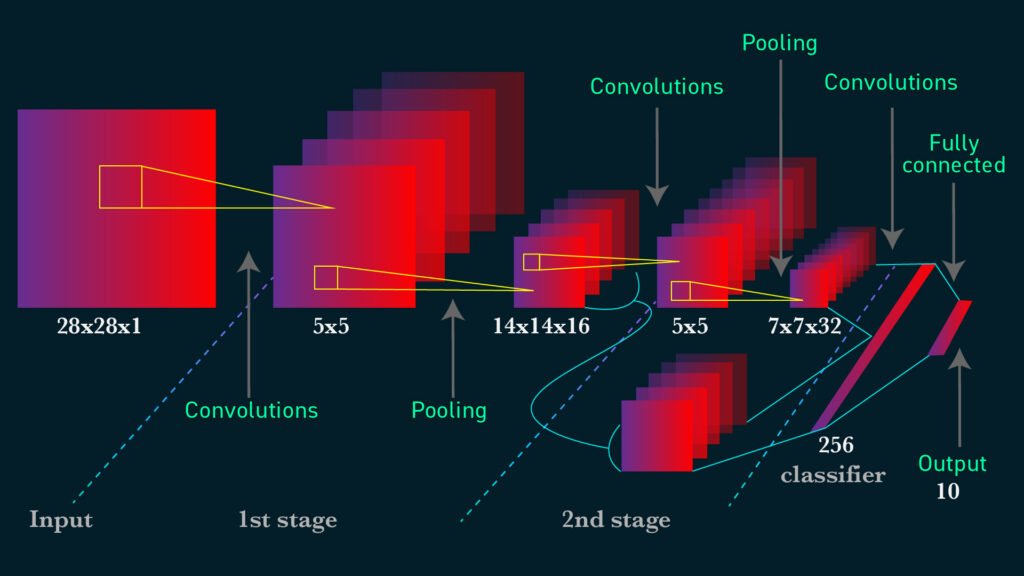
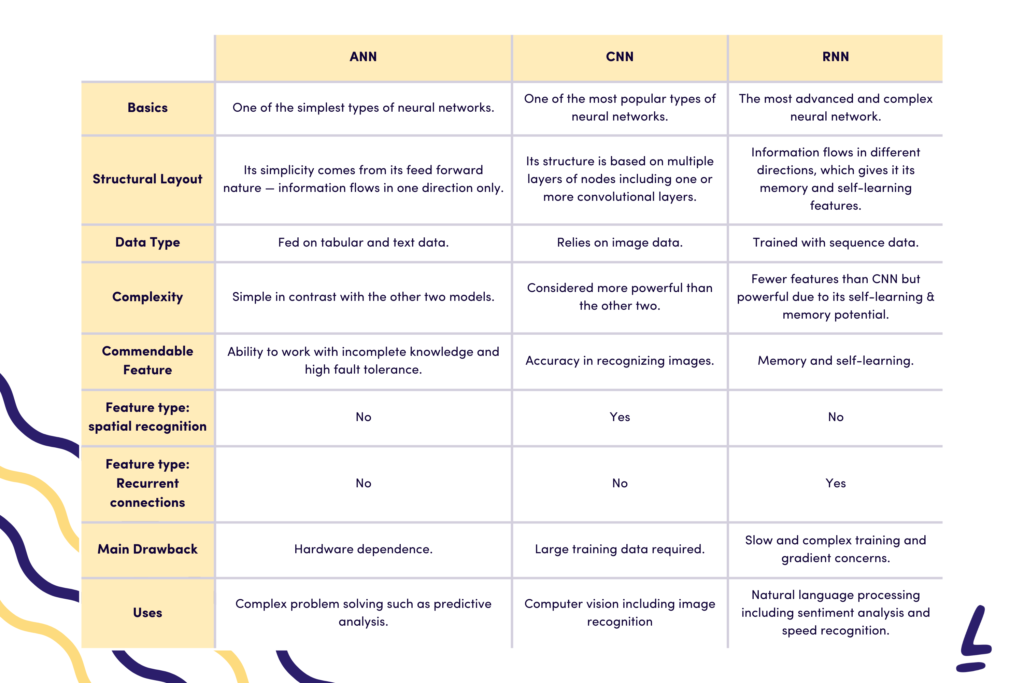
How CNNs Compare to Other Neural Networks:
- Fully Connected Networks (FCNs):
- Structure: In FCNs, every neuron is connected to every other neuron in the next layer. This can be computationally expensive for image data.
- Limitation: FCNs are less efficient for tasks like image recognition where spatial relationships matter.
- Recurrent Neural Networks (RNNs):
- Structure: RNNs handle sequential data, such as text or time series, by having connections that loop back.
- Limitation: While RNNs are great for sequences, CNNs are better for analyzing spatial data like images.
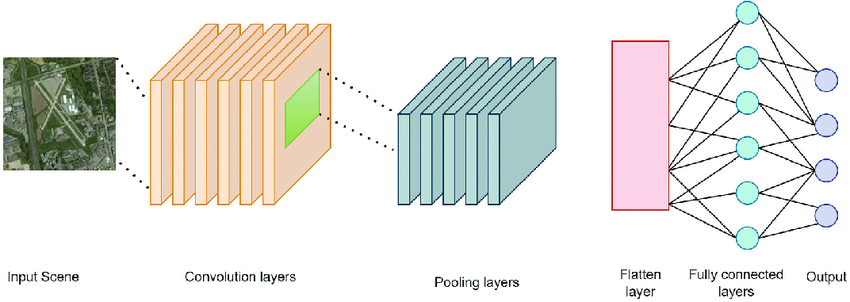
Core Components of CNNs:
- Convolutional Layers: These layers apply filters to an image to extract features like edges and textures. It’s like sliding a small window over the image to pick out patterns.
- Activation Functions: Functions like ReLU (Rectified Linear Unit) help the network learn complex features by adding non-linearity to the model.
- Pooling Layers: These layers simplify the data by reducing its size while keeping important information. For example, max pooling selects the highest value in a region to represent the data.
- Fully Connected Layers: After feature extraction, these layers combine the features to make predictions or classifications.
Example: Image Classification
Imagine you want to build a system that can identify different animals in photos. Here’s how a CNN would approach this:
- Detect Features: The CNN looks for basic features in the image, like edges or textures, using convolutional layers.
- Enhance Features: Activation functions like ReLU highlight important features and help the network understand more complex patterns.
- Simplify Data: Pooling layers reduce the image’s size while retaining the key features, making the network more efficient.
- Classify: Fully connected layers take the processed features and decide what animal is in the photo, such as a “cat” or “dog”.
CNNs are incredibly effective at analyzing visual data by learning and recognizing patterns through a series of specialized layers. They are essential for many technologies we use today, making them a fascinating and valuable area of artificial intelligence.
Convolutional Neural Networks (CNNs) are a crucial part of modern AI and deep learning. To understand their origin, you can explore the history of CNNs on Wikipedia.
History and Evolution of CNNs
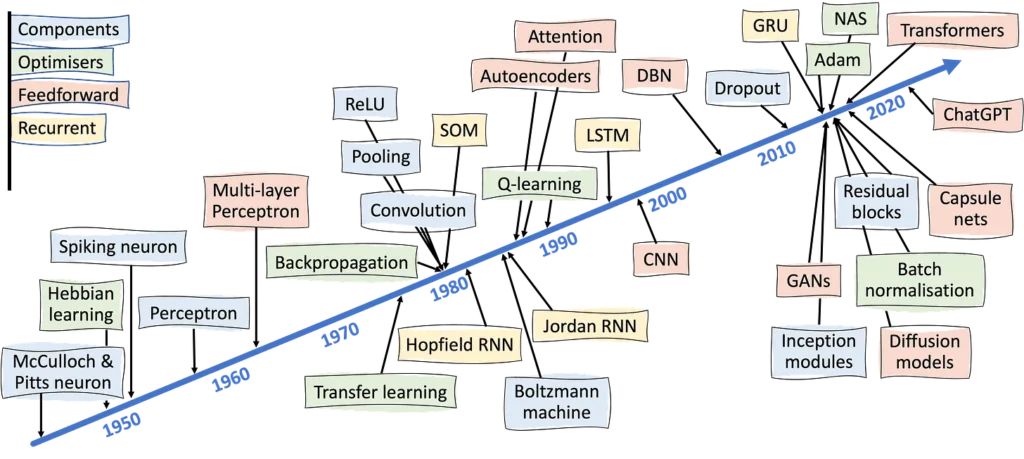
Early Developments
- 1960s: David Hubel and Torsten Wiesel, neuroscientists, discover hierarchical visual processing in the brain, which inspires the future development of CNNs.
- 1980: Kunihiko Fukushima introduces the Neocognitron, a neural network model inspired by the visual system of animals, laying the foundation for convolutional neural networks.
- 1989: Yann LeCun develops LeNet-5, one of the first CNN models, which revolutionized image recognition tasks like handwritten digit recognition using backpropagation.
Major Milestones and Breakthroughs
2012
- The introduction of AlexNet by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton wins the ImageNet competition, reducing error rates by nearly half and bringing CNNs into the spotlight. The model’s use of ReLU activation functions and GPU acceleration played a key role in this breakthrough.
2014
- VGGNet by the Visual Geometry Group at Oxford University emphasizes network depth, showing that increasing the number of layers (using small 3×3 filters) can significantly improve performance in image recognition tasks.
- GoogLeNet (Inception V1) by Google introduces Inception modules, allowing for multi-scale feature detection within the network, optimizing computational efficiency while maintaining high accuracy.
2015
- ResNet (Residual Networks) by Kaiming He and his team at Microsoft Research introduces residual learning, enabling the creation of very deep networks (up to 152 layers) without the vanishing gradient problem. ResNet’s architecture becomes a benchmark in the field.
- 2017: Capsule Networks (CapsNets) are introduced by Geoffrey Hinton and his team, proposing an alternative to traditional CNNs by focusing on preserving the spatial hierarchies of features.
2018
- EfficientNet, introduced by Mingxing Tan and Quoc V. Le at Google, provides a family of models that scale up the network width, depth, and resolution in a balanced manner, achieving state-of-the-art accuracy with fewer parameters.
- GANs (Generative Adversarial Networks), although not strictly CNNs, start incorporating CNN architectures for image generation tasks, leading to advancements in deepfake technology and other creative AI applications.
2020
- Vision Transformers (ViTs) emerge as an alternative to CNNs for image processing tasks. Although not CNNs, ViTs challenge the dominance of CNNs in computer vision by using transformer architectures, which were originally designed for natural language processing (NLP).
2022-2024
- Swin Transformers and Hybrid CNN-Transformer Architectures gain traction, combining the strengths of CNNs in local feature extraction with transformers’ ability to model global dependencies, leading to improvements in tasks like object detection and image segmentation.
- Continued refinement and optimization of CNN architectures focus on efficiency and performance, including advancements in AutoML and Neural Architecture Search (NAS), which automate the design of CNN models.
2024 and Beyond
- CNNs continue to evolve, with ongoing research focusing on improving efficiency, robustness, and adaptability across various domains, from healthcare to autonomous systems. Hybrid models combining CNNs with transformers and other architectures are at the forefront of research, promising new breakthroughs in AI and machine learning.
Key Components of a Convolutional Neural Network (CNN)
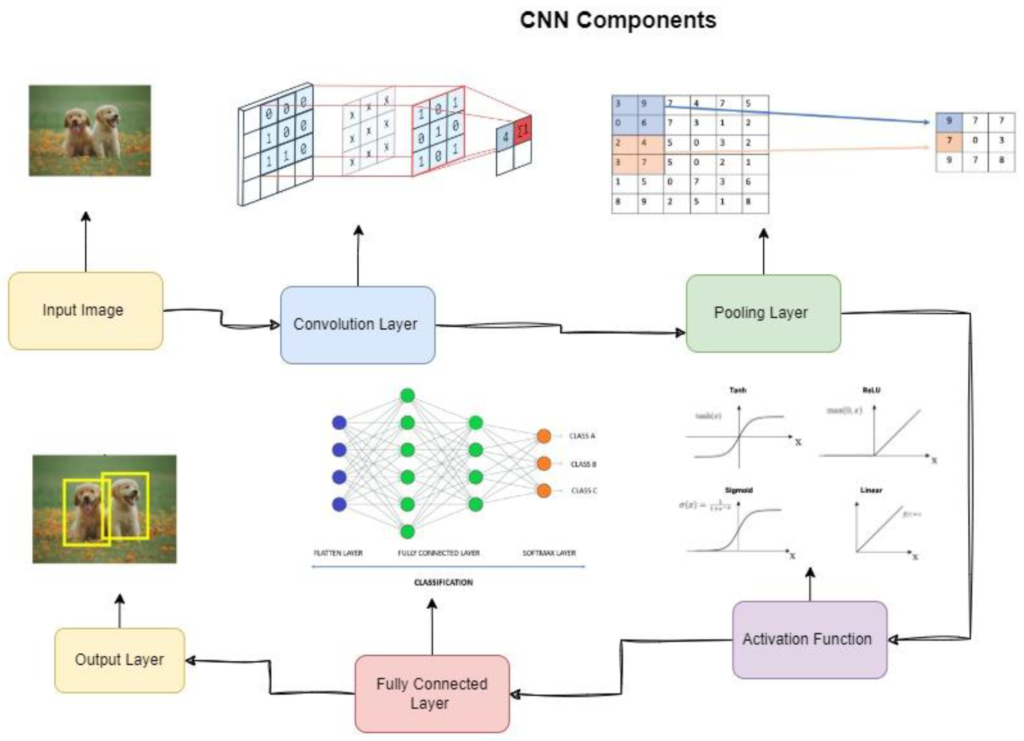
Convolutional Neural Networks (CNNs) are designed to process and analyze visual data through several key components. These include Convolutional Layers, Activation Functions, Pooling Layers, and Fully Connected Layers. Here’s a brief overview of each component:
Convolutional Layers
- Function : Extract features from input data using convolution operations.
- Input Data : Typically a 3D matrix (e.g., a 32×32 RGB image).
- Feature Detector (Filter/Kernels) : Small matrices (e.g., 3×3) that slide over the image, performing element-wise multiplication and summing results to create feature maps.
- Parameter Sharing : The same filter is used across the image to detect features like edges or textures.
- Hyperparameters
- Number of Filters : Determines the depth of the output feature maps.
- Stride : Controls the movement of the filter, affecting the size of the output.
- Padding : Adds zeros to the edges of the input (Valid, Same, Full) to manage filter size.
Activation Functions
- ReLU (Rectified Linear Unit) : Replaces negative values with zero, adding non-linearity and helping with training.
- Sigmoid and Tanh : Less common in CNNs; used for specific tasks like binary classification (Sigmoid) or feature scaling (Tanh).
Pooling Layers
- Purpose : Reduce spatial dimensions of feature maps, which decreases computation and helps prevent overfitting.
- Types
- Max Pooling : Selects the maximum value in each patch of the feature map.
- Average Pooling : Computes the average value in each patch.
- Effects : Simplifies the feature map while retaining key information.
Fully Connected Layers
- Function : Perform classification or regression by connecting every neuron to all neurons in the previous layer.
- Structure : Flattened feature maps from the previous layers are input into these layers.
- Role in Classification : Combines features to make final predictions, often using a softmax function to convert scores into probabilities for classification.
If you’re new to the concept of deep learning, you might want to read our Deep Learning Overview for a comprehensive introduction.
How CNNs Work: A Step-by-Step Guide
Convolution Operation
The convolution operation is fundamental to how Convolutional Neural Networks (CNNs) process and understand images. It allows CNNs to detect essential features such as edges, corners, and textures, which are crucial for tasks like image recognition and classification.
Explanation of Convolutions
Convolutions involve taking a small matrix, known as a filter or kernel, and sliding it over the input image. At each position, a dot product is calculated between the filter’s values and the corresponding pixels of the image. This dot product produces a single value that forms part of a new matrix, called a feature map or convolved feature. This feature map represents how strongly the pattern captured by the filter is present at each location in the image.
This operation effectively reduces the spatial size of the image, focusing on the most relevant features, while retaining the important spatial relationships within the data.
Role of Filters and Kernels
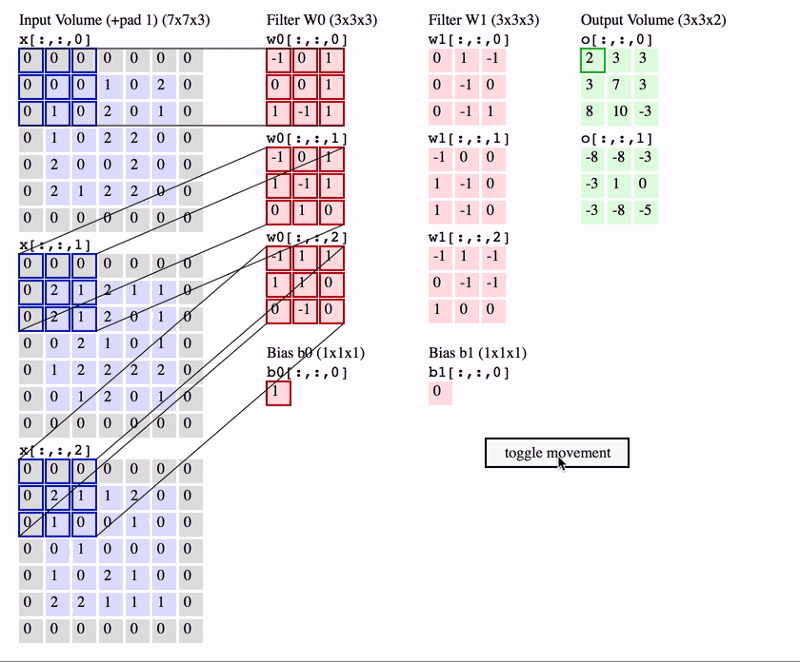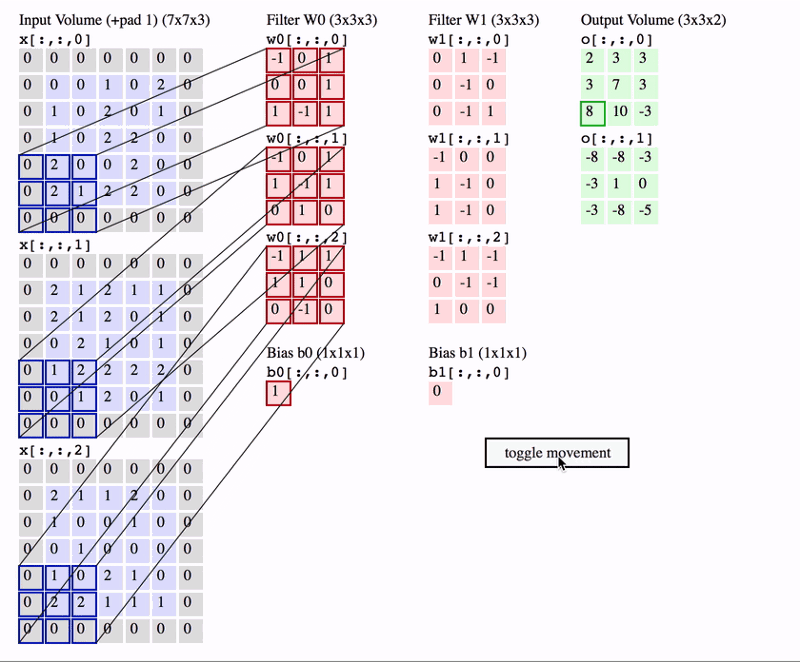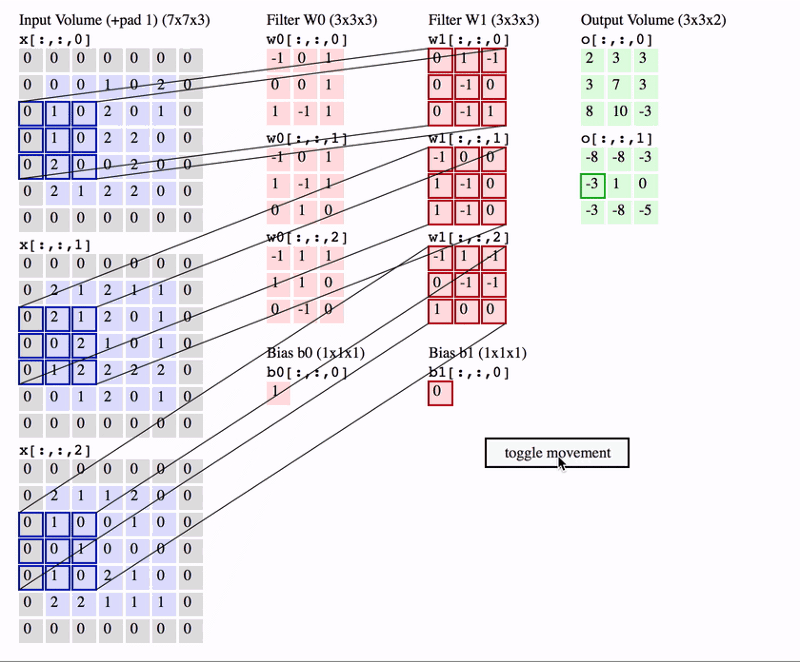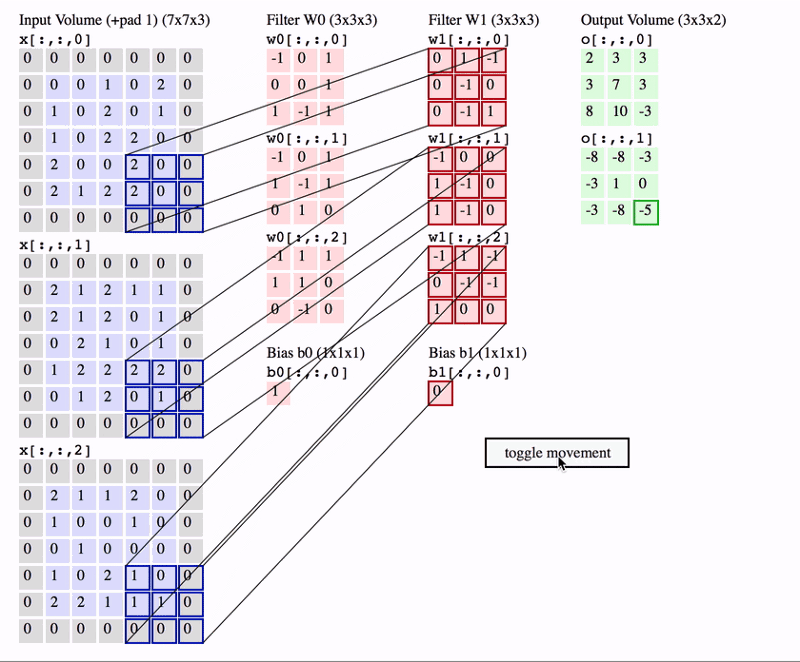
- Filters/Kernels are the central elements in the convolution operation. Typically, these are small grids, such as (3 x 3) or (5 x 5) matrices, that slide over the image to detect specific patterns.
- Learnable Parameters: The values within these filters are initially random but are learned during the training process. This means the CNN can adapt its filters to recognize different features relevant to the task at hand, such as detecting edges, textures, or specific shapes.
- Multiple Filters: In practice, multiple filters are used in a single convolutional layer. Each filter detects a different feature in the image, resulting in several feature maps that together give a rich representation of the image’s content.
For instance, in a digit recognition task, one filter might learn to detect horizontal edges, another might focus on vertical edges, and another might highlight curves. These combined features help the CNN understand the overall structure of the digit.
Example of Convolutional Operation
Let’s consider an example where we apply a (3 x 3) filter to a grayscale image of a handwritten digit.
- Sliding the Filter: The filter starts at the top-left corner of the image and slides across each pixel, moving right by a defined stride (usually 1 pixel at a time). At each position, a dot product is calculated between the filter and the corresponding section of the image.
- Calculating the Dot Product: Suppose our filter is designed to detect vertical edges. As the filter slides over the image, it calculates how much each part of the image aligns with a vertical edge pattern. If the alignment is strong, the dot product will result in a high value, which is placed in the corresponding position in the feature map.
- Generating the Feature Map: This process continues until the filter has covered the entire image. The resulting feature map shows where vertical edges are present in the image, with higher values indicating stronger matches.
- Impact of Stride and Padding: The stride determines how far the filter moves at each step, affecting the resolution of the feature map. Padding can be added around the edges of the image to ensure the filter fits, preserving the original image size in the output.
For example, if the input image is a (28 x 28) grid of pixels, using a (3 x 3) filter with a stride of 1 and same padding would result in a (28 x 28) feature map. If the stride were 2, the feature map would be smaller, capturing only the most prominent features.
Activation Functions
Common Functions (e.g., ReLU, Sigmoid, Tanh)
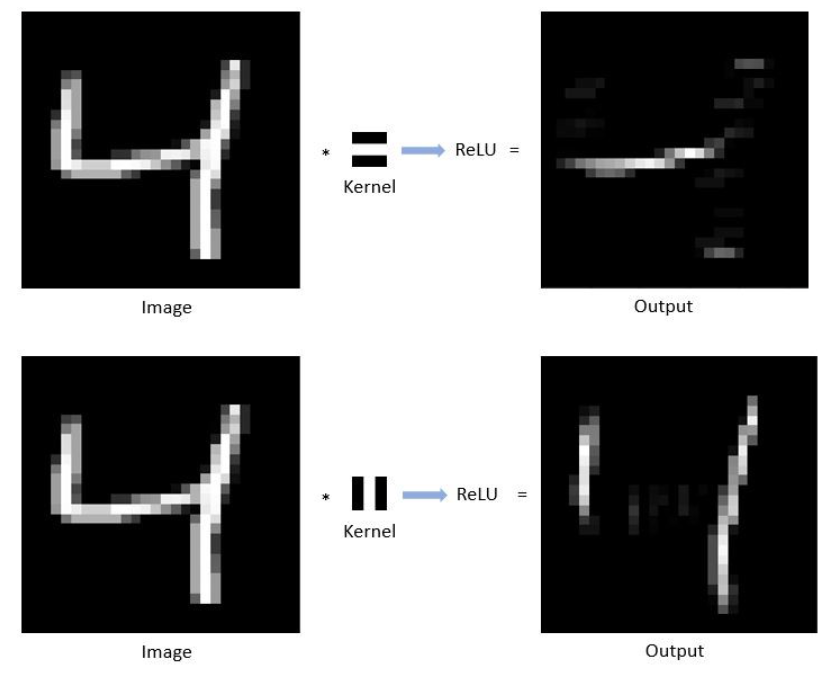
- ReLU (Rectified Linear Unit): ReLU is the most commonly used activation function in CNNs due to its simplicity and effectiveness. It replaces all negative values in the feature map with zero while keeping positive values unchanged. This introduces non-linearity into the model, allowing it to learn complex patterns.
- Sigmoid: The Sigmoid function squashes input values to a range between 0 and 1. It’s often used in binary classification tasks. However, it can suffer from the vanishing gradient problem, making it less popular in deeper networks.
- Tanh (Hyperbolic Tangent): Tanh is similar to Sigmoid but squashes input values to a range between -1 and 1, making it zero-centered. It is often preferred over Sigmoid in hidden layers because it tends to perform better, although it can still suffer from the vanishing gradient problem.
Their Role and Impact
Activation functions introduce non-linearity into the network, enabling CNNs to learn and model complex data. Without these functions, the network would only be able to learn linear relationships, significantly limiting its effectiveness.
- ReLU: Helps in faster training and mitigates the vanishing gradient problem, which makes it the preferred choice for CNNs.
- Sigmoid and Tanh: Are more commonly used in output layers, especially in binary or multi-class classification tasks.
Pooling Layers
Max Pooling vs. Average Pooling
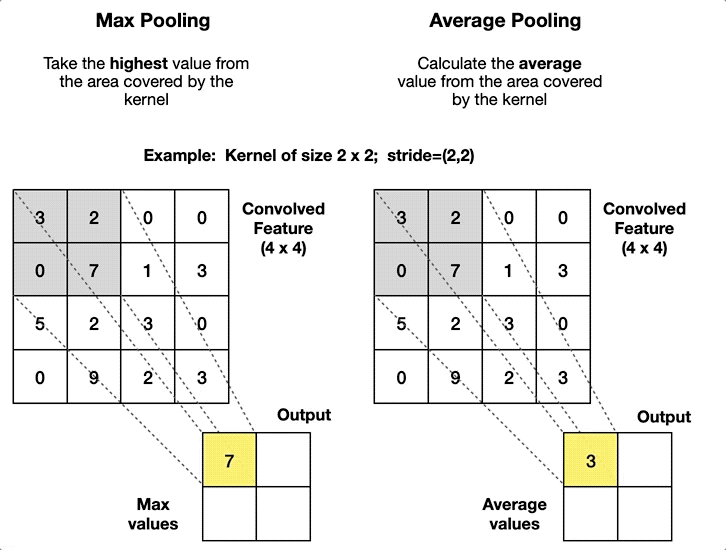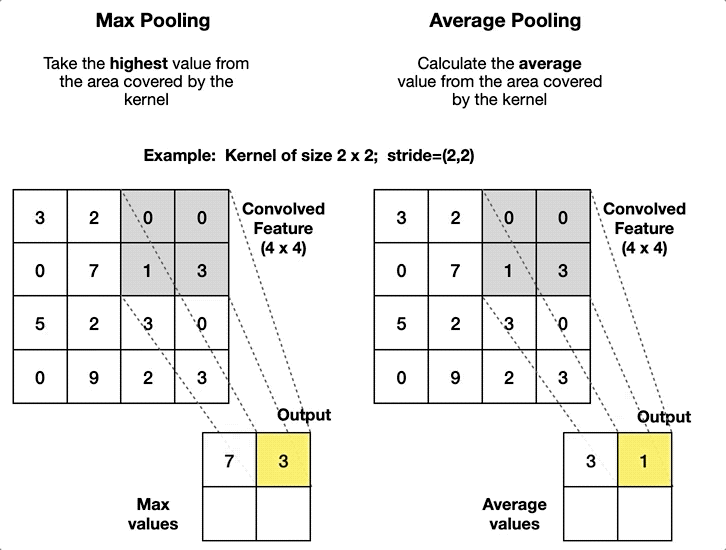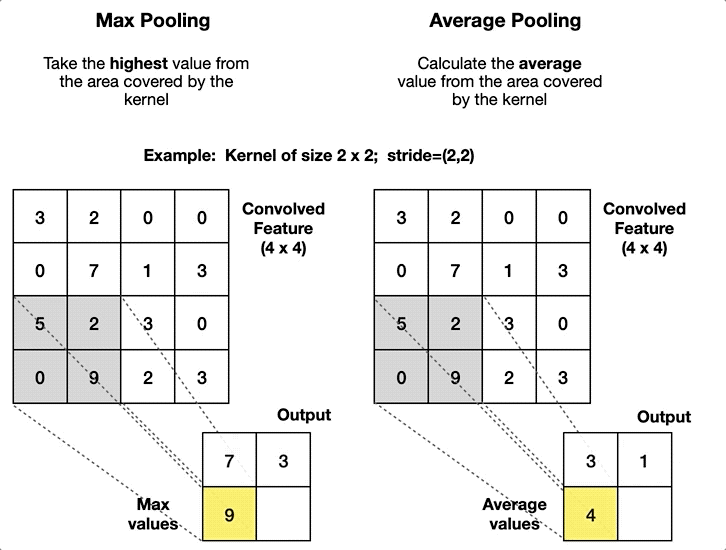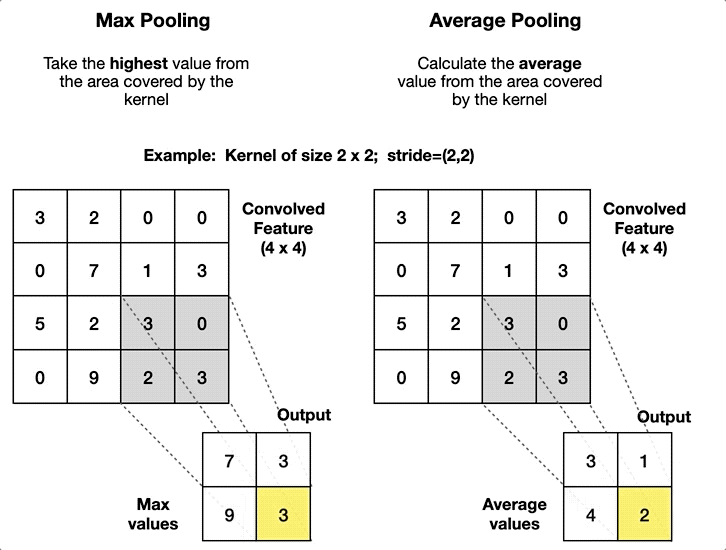
- Max Pooling: This operation selects the maximum value from the filter’s receptive field as it slides over the input. Max pooling is more common because it retains the most prominent features, which are crucial for understanding images.
- Average Pooling: Instead of taking the maximum value, average pooling calculates the average of the values within the filter’s receptive field. While it’s less common than max pooling, it can be useful in specific scenarios where a smoother output is desired.
Purpose and Effects on Feature Maps
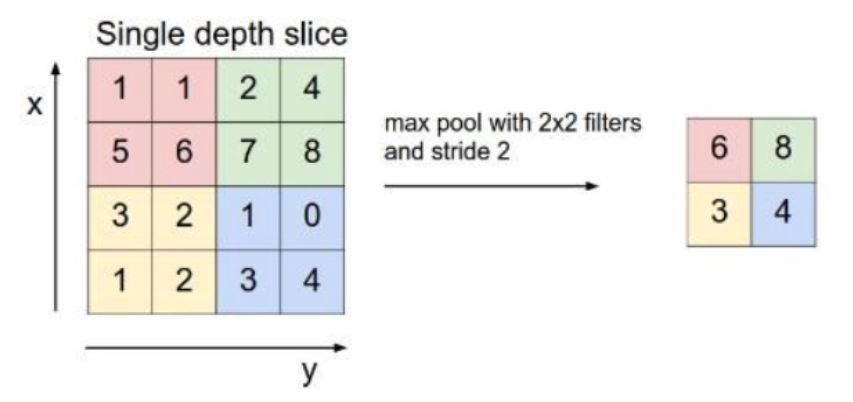
Pooling layers reduce the spatial dimensions (height and width) of the feature maps, which has several benefits:
- Dimensionality Reduction: Reduces the amount of computation and the number of parameters, speeding up the training process and reducing memory usage.
- Feature Highlighting: By retaining the most significant features (especially in max pooling), the network becomes more robust in recognizing patterns even in slightly transformed images.
- Mitigation of Overfitting: Pooling helps in generalizing the model by reducing its sensitivity to the exact position of features within the image.
Fully Connected Layers
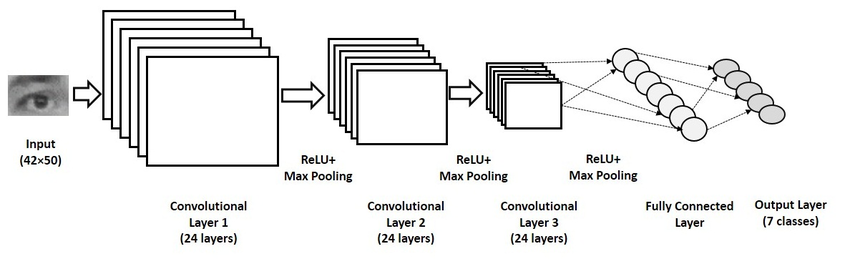
Transition from Convolutional Layers
After passing through several convolutional and pooling layers, the high-level features extracted from the images are fed into fully connected layers. Here, the 2D feature maps are flattened into a 1D vector, which is then passed through a series of fully connected layers.
Role in Classification
Fully connected layers perform the task of classification. They take the learned features from previous layers and map them to the final output. Each neuron in these layers is connected to every neuron in the previous layer, allowing the network to learn complex combinations of features.
- Softmax Activation: In the final layer, a softmax function is typically applied in multi-class classification tasks. It outputs a probability distribution over the classes, helping the model decide the most likely category for the input image.
Training CNNs
Backpropagation and Gradient Descent

- Backpropagation: This algorithm is used to calculate the gradients of the loss function with respect to each weight in the network. By propagating the error backward through the network, backpropagation updates the weights to minimize the loss function.
- Gradient Descent: Gradient descent is the optimization algorithm that adjusts the weights of the CNN. By computing the gradient of the loss function, it moves the weights in the direction that reduces the error.
Common Optimization Algorithms (e.g., Adam, SGD)
- SGD (Stochastic Gradient Descent): A variant of gradient descent, SGD updates the model’s weights based on a single training example or a small batch. While faster than traditional gradient descent, it can be noisy, which sometimes helps in escaping local minima.
- Adam (Adaptive Moment Estimation): Adam is an advanced optimization algorithm that combines the benefits of both SGD and RMSprop (Root Mean Square Propagation). It adapts the learning rate for each parameter, making it more efficient and effective in training deep networks.
For a more technical dive into CNN architecture, refer to Stanford’s CS231n course.
Key Concepts in Convolutional Neural Networks (CNNs)
Understanding these key concepts helps in grasping how CNNs effectively analyze and classify images.
Feature Maps
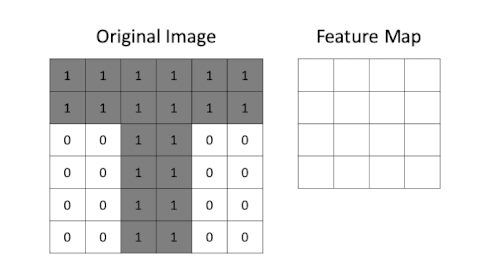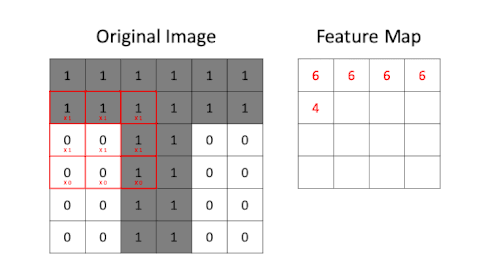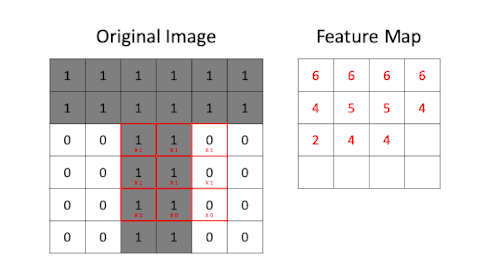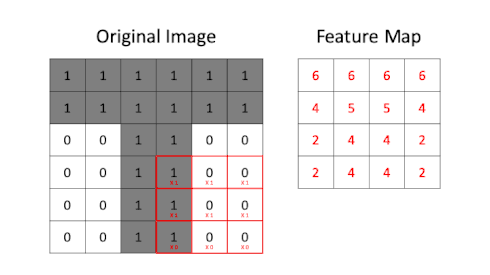
- Definition and Importance
- Feature maps are the result of applying filters to the input image in the convolutional layers. They highlight specific features or patterns detected by the filters, such as edges, textures, or shapes.
- They are crucial because they represent the extracted features that are used for further processing and classification.
- Hierarchical Feature Learning
- CNNs learn features in a hierarchical manner. Early layers detect basic features (e.g., edges and corners), while deeper layers combine these features to detect more complex patterns (e.g., textures and object parts).
- This hierarchical approach allows CNNs to capture a wide range of features at various levels of abstraction.
Stride and Padding
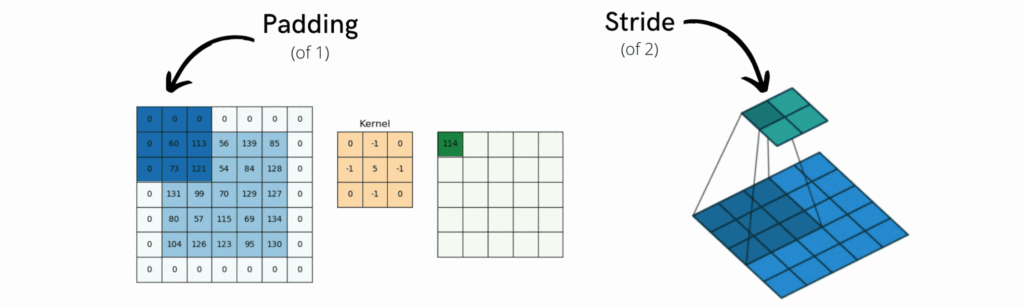
- Stride
- Definition: Stride is the number of pixels by which the filter moves over the input image during convolution. A stride of 1 means the filter moves one pixel at a time.
- Effects on Output Size: A larger stride reduces the size of the output feature map because the filter covers more area per step, resulting in fewer steps and hence a smaller feature map.
- Padding
- Definition: Padding adds extra pixels around the border of the input image to control the spatial dimensions of the output feature map.
- Types and Effects
- Valid Padding: No padding; the filter only covers the valid part of the image, which can reduce the size of the output feature map.
- Same Padding: Adds enough padding to keep the output feature map the same size as the input.
- Full Padding: Increases the size of the output feature map by adding zeros around the input image.
- Practical Examples
- For instance, using a 3×3 filter with a stride of 2 on a 32×32 image will produce a smaller feature map compared to using a stride of 1.
- Applying same padding to a 32×32 image with a 3×3 filter keeps the output size at 32×32.
Batch Normalization
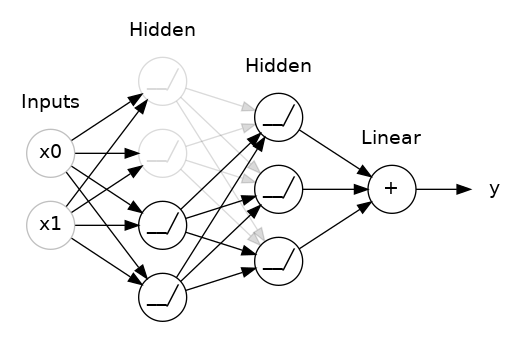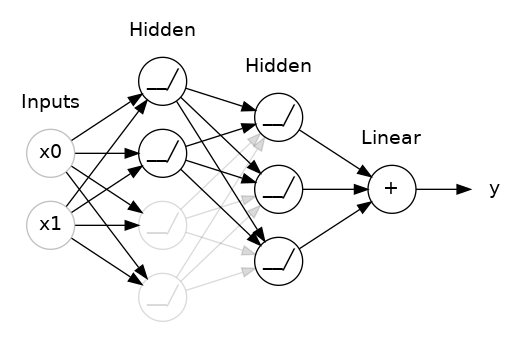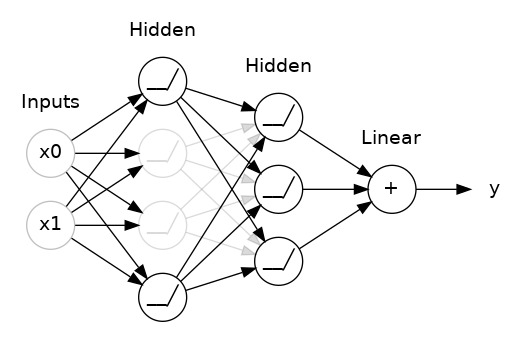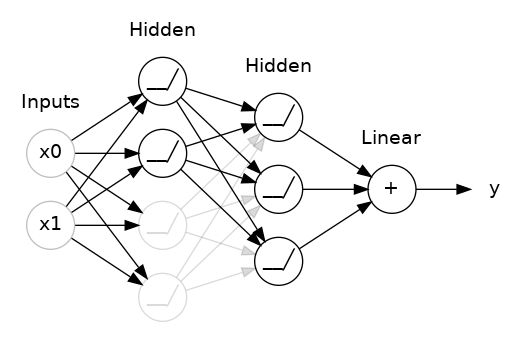
- Purpose and Benefits
- Batch normalization normalizes the inputs of each layer to have zero mean and unit variance, which helps stabilize and accelerate the training process.
- It reduces internal covariate shift, improves gradient flow, and can act as a regularizer.
- How it Improves Training
- By normalizing the activations, batch normalization helps in mitigating issues like vanishing or exploding gradients, leading to faster convergence and better performance.
- It often reduces the need for dropout and can allow for higher learning rates.
Dropout
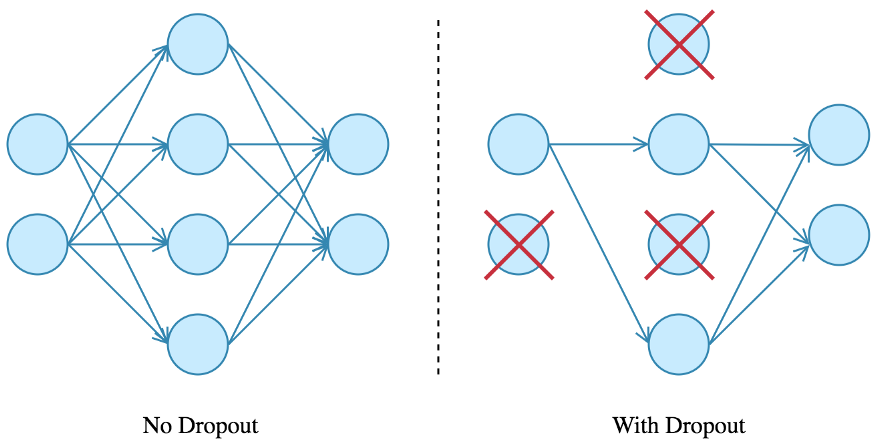
- Concept and Role in Regularization
- Dropout is a regularization technique where random neurons are “dropped out” or deactivated during training. This prevents neurons from co-adapting too much and encourages the network to learn more robust features.
- Implementation and Impact on Performance
- Dropout is typically applied during training and involves randomly setting a fraction of neurons to zero with a specified probability (e.g., 0.5).
- It helps reduce overfitting and improves the generalization of the model. During inference, dropout is turned off, and all neurons are used to make predictions.
Types of CNN Architectures
Convolutional Neural Networks (CNNs) have evolved significantly over the years, with each new architecture bringing innovations that enhance performance and capability. Here’s a detailed overview of some key CNN architectures:
LeNet-5

- Overview and Historical Significance
- LeNet-5 was developed by Yann LeCun et al. in 1998 and is a pioneering 7-layer CNN designed for digit classification (e.g., the MNIST dataset).
- It marked a significant milestone by demonstrating the practical application of CNNs in recognizing handwritten digits.
- Key Features and Architecture
- Input: 32×32 pixel grayscale images.
- Layers
- Convolutional Layers: Extract features using small 5×5 kernels.
- Pooling Layers: Subsampling with 2×2 max pooling.
- Fully Connected Layers: Two dense layers leading to a 10-class output.
- Application: Used by banks for check processing, constrained by computing resources due to its limitations with higher resolution images.
AlexNet

- Innovations Introduced
- AlexNet, developed by Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever in 2012, significantly advanced CNN technology by winning the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) with a top-5 error rate of 15.3%.
- It outperformed previous models by a substantial margin (previous top-5 error rate was around 26.2%).
- Key Features and Architecture
- Input: 224×224 RGB images.
- Layers
- Convolutional Layers: Utilizes 11×11, 5×5, and 3×3 kernels.
- Pooling: Max pooling layers for dimensionality reduction.
- Activation: ReLU applied after each convolutional and fully connected layer.
- Regularization: Dropout and data augmentation techniques.
- Training: Used two Nvidia GeForce GTX 580 GPUs, split into two pipelines.
- Impact: Introduced deep learning to a wider audience and set new benchmarks in image classification.
ZFNet
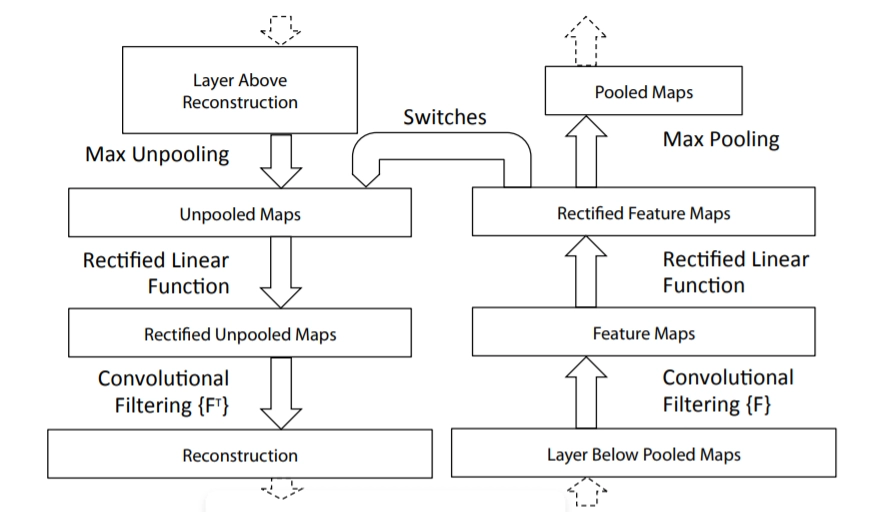
- Overview
- ZFNet, developed by Matthew Zeiler and Rob Fergus in 2013, improved on AlexNet by fine-tuning hyperparameters and adding new deep learning elements.
- It achieved a top-5 error rate of 14.8%, demonstrating the effectiveness of refined model parameters.
- Key Features
- Architecture: Maintained AlexNet’s structure with modifications in hyperparameters and additional features.
- Impact: Continued the trend of incremental improvements leading to even better performance on image classification tasks.
GoogLeNet (Inception v1)
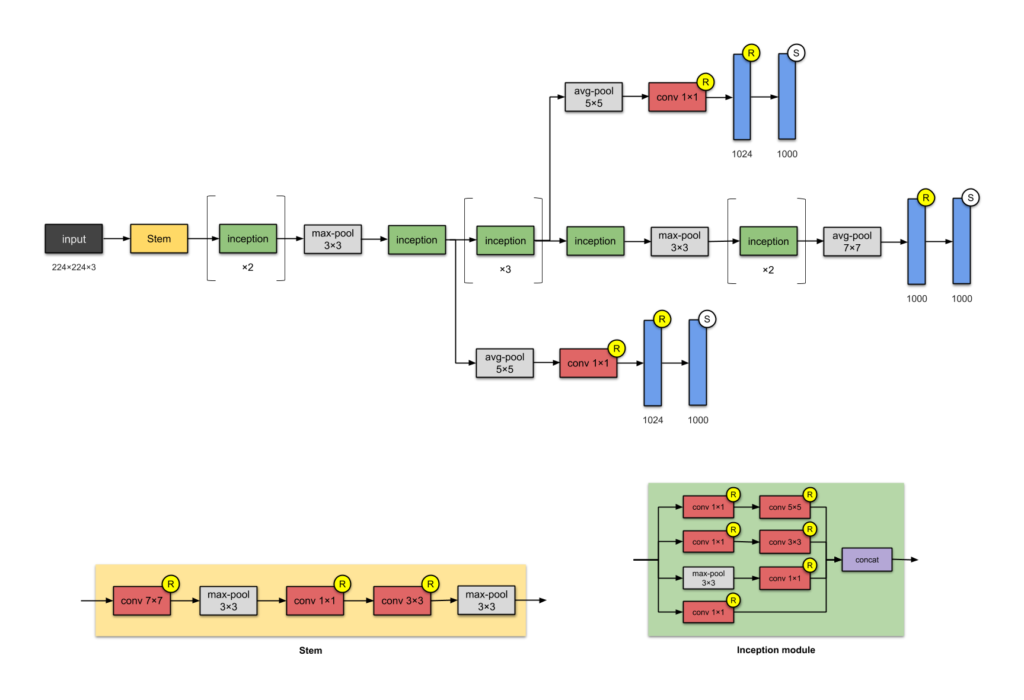
- Overview
- GoogLeNet (Inception v1), introduced by Google in 2014, won the ILSVRC 2014 competition with a top-5 error rate of 6.67%, showcasing near-human-level performance.
- It introduced the concept of Inception modules, which allowed for more efficient feature extraction.
- Key Features and Architecture
- Input: 224×224 RGB images.
- Inception Modules: Use parallel convolutions with different kernel sizes and pooling operations to capture multi-scale features.
- Batch Normalization: Applied to stabilize and accelerate training.
- Parameters: Reduced from 60 million (AlexNet) to 4 million, significantly lowering computational complexity.
- Impact: Demonstrated the effectiveness of multi-scale processing and reduced parameter count in deep networks.
VGGNet

- Overview
- VGGNet, developed by the Visual Geometry Group (Simonyan and Zisserman) in 2014, was the runner-up in ILSVRC 2014. It is known for its simplicity and uniformity.
- Key Features and Architecture
- Input: 224×224 RGB images.
- Layers: Consists of 16 convolutional layers with very small 3×3 kernels.
- Pooling: Max pooling layers to reduce spatial dimensions.
- Parameters: 138 million, making it computationally intensive but highly effective for feature extraction.
- Impact: Popular for transfer learning and feature extraction due to its well-documented weights and architecture.
ResNet
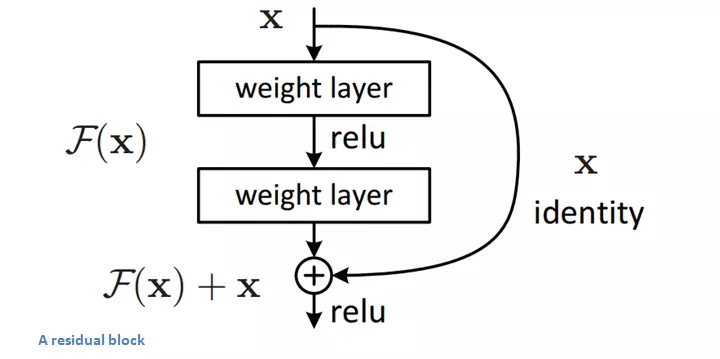
- Overview
- ResNet, introduced by Kaiming He et al. in 2015, won the ILSVRC 2015 with a top-5 error rate of 3.57%, surpassing human-level performance.
- Key Features and Architecture
- Residual Learning: Introduced skip connections (residual blocks) that allow gradients to flow more easily through very deep networks.
- Layers: Enabled training of networks with up to 152 layers while maintaining manageable complexity.
- Batch Normalization: Heavily utilized to stabilize and speed up training.
- Impact: Revolutionized deep learning by addressing training challenges in very deep networks and setting new performance benchmarks.
CNNs in Real-World Applications
Convolutional Neural Networks (CNNs) have revolutionized the way we analyze and interpret visual data. By automatically learning and extracting features from images, CNNs have become instrumental in various applications, driving advancements across multiple industries. From enhancing search engine functionality to revolutionizing medical diagnostics, the impact of CNNs is profound and far-reaching.
Image Classification
Search Engines: CNNs enhance search engine capabilities by accurately categorizing and tagging images based on their content. This facilitates improved image retrieval and relevance in search results.
Social Media: In platforms like Facebook and Instagram, CNNs automate the tagging of individuals and objects in photos, which enhances user interaction and streamlines content organization.
Recommender Systems: Retailers and content providers, such as Amazon and Pinterest, use CNNs to analyze visual features of products or content, generating personalized recommendations based on users’ past interactions and visual preferences.
Object Detection
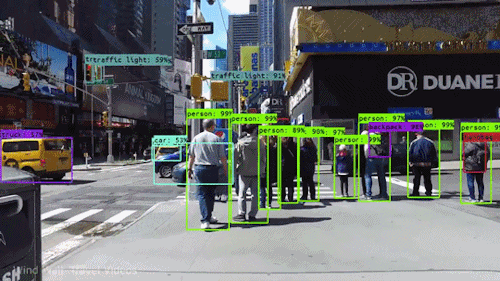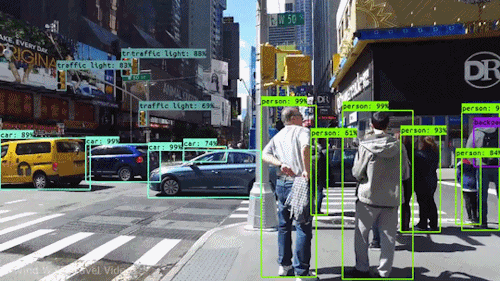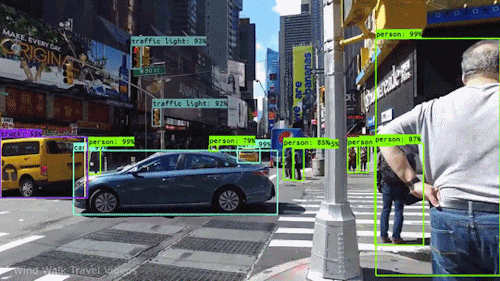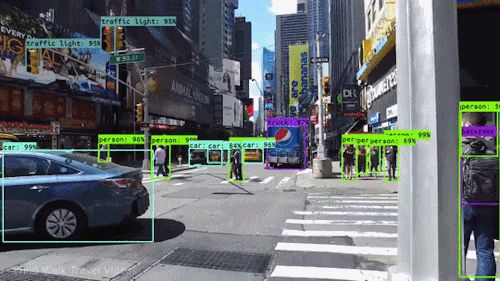
Real-Time Surveillance: CNNs are employed in security systems to detect and track objects in live video feeds. This technology is crucial for monitoring public spaces, enhancing security protocols, and identifying suspicious activities.
Autonomous Vehicles: Self-driving cars rely on CNNs to identify and classify various objects in their environment, including pedestrians, other vehicles, and road signs. This real-time object detection is essential for safe navigation and collision avoidance.
Image Segmentation

Medical Imaging: In healthcare, CNNs segment complex structures within medical scans, such as MRI or CT images. This capability aids radiologists in accurately identifying tumors, fractures, and other anomalies, leading to more precise diagnoses and treatment plans.
Autonomous Vehicles: CNNs improve the understanding of vehicle surroundings by segmenting different elements in the visual field, such as lanes, road signs, and obstacles. This detailed analysis supports better decision-making and enhances driving safety.
Style Transfer

Art and Media: CNNs enable the application of artistic styles to images and videos, allowing for creative transformations that mimic famous art styles or create entirely new visual effects. This technology is widely used in digital art and media production.
Advertising: Marketers use style transfer to generate visually appealing advertisements by applying artistic effects to product images or promotional materials, making them more engaging and memorable.
Face Recognition
Social Media: Platforms like Facebook use CNNs for automated photo tagging, recognizing and matching faces across numerous images. This feature simplifies the tagging process, particularly in large photo collections from events or social gatherings.
Security Systems: Facial recognition technology enhances security through biometric identification, enabling secure access control and monitoring in various settings, including airports, banks, and corporate environments.
Video Analytics

Action Detection: CNNs analyze video footage to detect and classify actions or behaviors, such as identifying specific activities in sports events or security breaches. This analysis is crucial for event monitoring and tactical decision-making.
Event Monitoring: CNNs are used to detect unusual or critical events, such as fires or accidents, in video feeds. By recognizing these anomalies, the technology facilitates prompt responses and emergency interventions.
Healthcare
Medical Image Computing: CNNs excel at detecting abnormalities in medical images, such as identifying tumors in cancer screenings or fractures in X-rays. This advanced image analysis supports early diagnosis and effective treatment strategies.
Health Risk Assessment: CNNs assess patient data to predict health risks and potential complications. By analyzing historical and real-time data, these systems assist in preventative care and personalized treatment planning.
Drug Discovery
Compound Analysis: CNNs accelerate the drug discovery process by analyzing chemical compounds and predicting their potential effectiveness and safety. This approach speeds up the identification of promising drug candidates.
Lead Optimization: During drug development, CNNs optimize lead compounds by analyzing their interactions and refining their properties. This process enhances the efficiency of drug discovery and reduces development time.
Autonomous Robotics
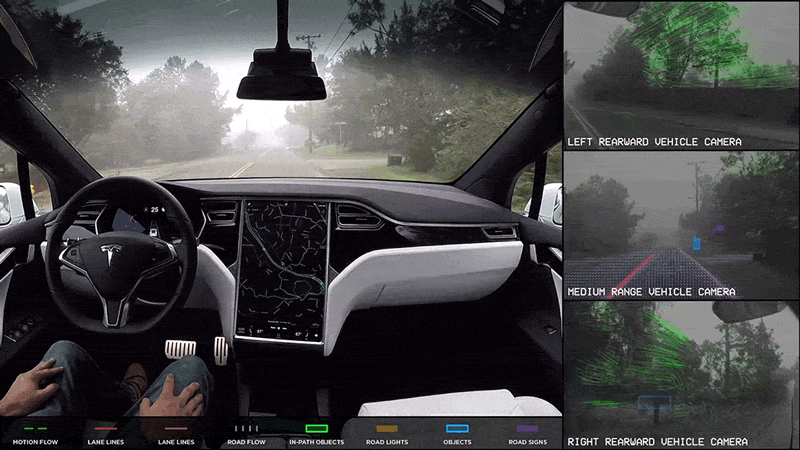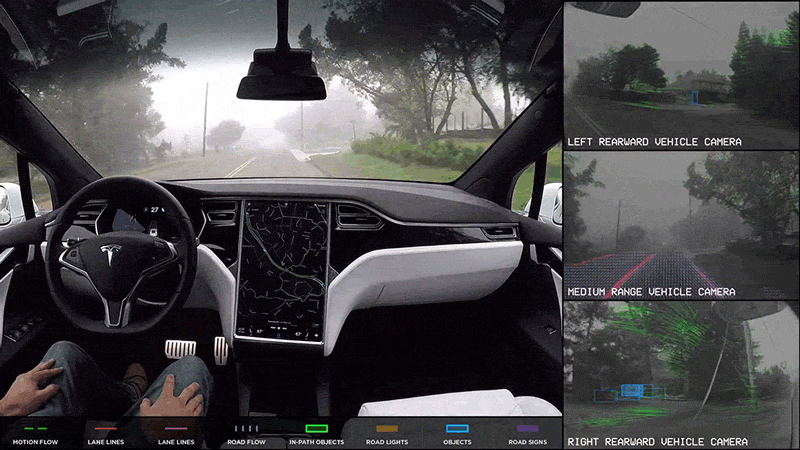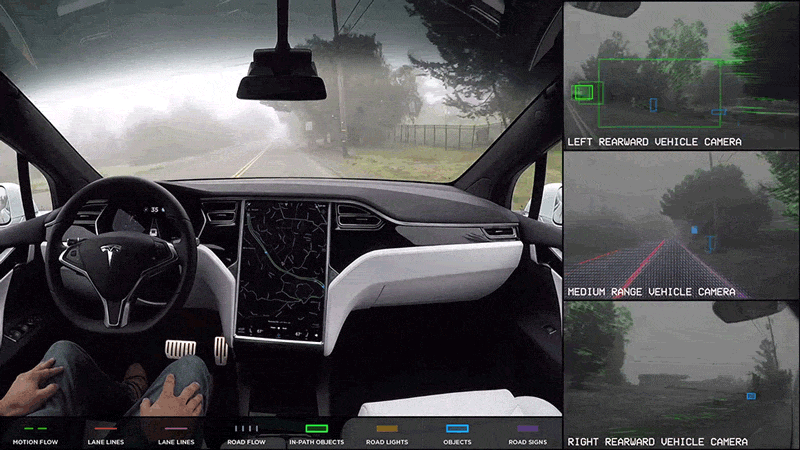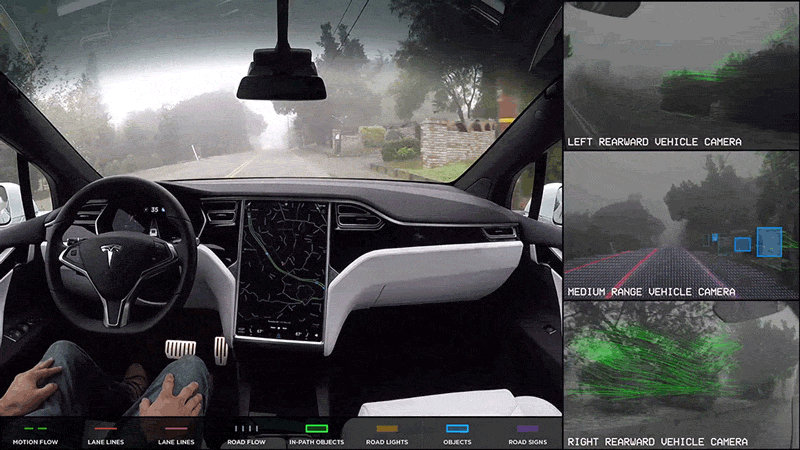
Navigation: In autonomous robots, CNNs process visual input to navigate complex environments. This includes obstacle detection and path planning, allowing robots to move efficiently and safely in dynamic settings.
Manipulation: CNNs enable robots to identify and manipulate objects based on visual information, improving their ability to perform tasks such as assembly, sorting, and interaction with objects in their environment.
Video Games
Player Behavior Analysis: In the gaming industry, CNNs analyze player behavior and engagement patterns to predict lifetime value (CLV) and tailor in-game experiences. This analysis helps developers understand player preferences and optimize game design.
Game Content Personalization: CNNs personalize gaming experiences by analyzing visual content and player interactions. This technology allows for dynamic content adjustments, enhancing player satisfaction and retention through targeted in-game features and recommendations.
For detailed case studies, you can also explore research articles on PubMed.
Future Trends and Research in CNNs
As Convolutional Neural Networks (CNNs) continue to evolve, several emerging trends and research directions are shaping the future of this technology. Here’s a look at some of the most notable advancements:
- Emerging Architectures and Techniques:
- Transformers in Vision: Recently, transformer models, originally designed for natural language processing, have been adapted for vision tasks, leading to architectures like Vision Transformers (ViTs). These models promise enhanced performance and flexibility in handling visual data.
- Efficient CNNs: New architectures focus on improving efficiency by reducing computational complexity and model size. Techniques such as depthwise separable convolutions and network pruning are being explored to make CNNs more accessible and faster without sacrificing accuracy.
- Self-Supervised Learning: This approach allows CNNs to learn from unlabeled data by generating their own labels. This has the potential to greatly reduce the need for large labeled datasets and improve generalization.
- Impact on Future AI Advancements:
- Enhanced Personalization: CNNs are expected to drive advancements in personalized experiences across various domains, from tailored content recommendations to adaptive user interfaces.
- Improved Healthcare: Continued innovation in CNNs will likely lead to more accurate and efficient diagnostic tools, predictive analytics, and personalized treatment plans, further revolutionizing medical care.
- Autonomous Systems: As CNNs evolve, their integration into autonomous systems will become more sophisticated, enhancing capabilities in areas like self-driving cars, robotics, and intelligent surveillance.
- Current Research Directions and Innovations:
- Explainable AI: Research is focused on making CNNs more interpretable, allowing users to understand how models make decisions and ensuring transparency in applications such as medical diagnostics and security.
- Cross-Domain Adaptation: Efforts are underway to improve CNNs’ ability to generalize across different domains and tasks, enhancing their versatility and applicability in varied real-world scenarios.
- Neurosymbolic Integration: Combining CNNs with symbolic reasoning approaches is being explored to create models that can leverage both visual perception and logical reasoning, leading to more robust AI systems.
These emerging trends and research directions highlight the dynamic nature of CNNs and their potential to drive significant advancements in AI technology and its applications.For further reading on AI and its various applications, explore our comprehensive collection of articles here.
Read More
- What is Deep Learning? The Definitive Game-Changing Guide for 2024
- 10 Key Insights: What Is Generative AI and How It Revolutionizes Technology
- 7 Powerful Innovations of AI in Healthcare Transforming Patient Care
- AI in Logistics: 8 Innovative Use Cases Enhancing Efficiency
- The Revolutionary Impact of AI in Education 2024: Transforming Learning and Teaching
- AI in E-Commerce: What 5 Supercharging Ways Does It Revolutionize Shopping?
- Curious About the Best AI Coding Assistants in 2024? Top 10 Revealed!
Conclusion
Convolutional Neural Networks (CNNs) have fundamentally reshaped our approach to visual data, driving advancements across various fields from medical imaging to autonomous vehicles. Their ability to learn and recognize patterns has opened new doors in AI.
As CNN technology continues to evolve, it’s an exciting time for anyone interested in AI. Dive deeper into their potential, experiment with new applications, and stay curious—CNNs are a gateway to the future of technology.





Přijetí hypoteční platby může být obtížné pokud nemáte rádi čekání v dlouhých řadách ,
vyplnění extrémní formuláře , a odmítnutí úvěru na
základě vašeho úvěrového skóre . Přijímání
hypoteční platby může být problematické, pokud nemáte rádi
čekání v dlouhých řadách , podávání extrémních formulářů , a odmítnutí úvěru na základě vašeho
úvěrového skóre . Přijímání hypoteční platby může být problematické ,
pokud nemáte rádi čekání v dlouhých řadách ,
vyplnění extrémních formulářů a odmítnutí
úvěrových rozhodnutí založených na úvěrových skóre .
Nyní můžete svou hypotéku zaplatit rychle a efektivně v České republice. https://groups.google.com/g/sheasjkdcdjksaksda/c/aVmIePO8mFk
Good – I should definitely pronounce, impressed with your web site. I had no trouble navigating through all the tabs and related information ended up being truly simple to do to access. I recently found what I hoped for before you know it in the least. Quite unusual. Is likely to appreciate it for those who add forums or anything, site theme . a tones way for your customer to communicate. Excellent task.
People find it much more appealing to view shirtless bodies than covered ones.
And a portion of the appeal is the vulnerability that comes with being naked and feeling a little ashamed or
exposed during foreplay. When both parties are in the brown, it
increases the intimacy of the gender. When their lover is resilient, dominance tends to appeal to some
folks. And let’s not forget about the nude porn:
they really go all out when it comes to showing off everyone, focusing
on penetration, and on private pieces. http://zutrax.org/__media__/js/netsoltrademark.php?d=www.shirvanbroker.az%2F2021%2F08%2F02%2Florem-ipsum-dolor-sit-amet-consecte-cing-elit-sed-do-eiusmod-tempor%2F
Přijetí hypoteční platby může být nebezpečný pokud nemáte rádi čekání v dlouhých řadách
, vyplnění mimořádné formuláře , a odmítnutí úvěru na základě vašeho úvěrového skóre .
Přijímání hypoteční platby může být problematické, pokud nemáte rádi
čekání v dlouhých řadách , podávání extrémních formulářů , a odmítnutí úvěru na základě vašeho úvěrového skóre .
Přijímání hypoteční platby může být problematické , pokud nemáte rádi čekání v dlouhých
řadách , vyplnění extrémních formulářů a odmítnutí úvěrových
rozhodnutí založených na úvěrových skóre .
Nyní můžete svou hypotéku zaplatit rychle a efektivně v České republice. https://groups.google.com/g/sheasjkdcdjksaksda/c/6Xp9eIrBxHk
I regard something genuinely interesting about your web blog so I saved to favorites.
Přijetí hypoteční platby může být problematické pokud nemáte rádi čekání v dlouhých řadách , vyplnění závažné formuláře , a
odmítnutí úvěru na základě vašeho úvěrového skóre .
Přijímání hypoteční platby může být problematické,
pokud nemáte rádi čekání v dlouhých řadách
, podávání extrémních formulářů , a
odmítnutí úvěru na základě vašeho úvěrového skóre .
Přijímání hypoteční platby může být problematické , pokud nemáte rádi čekání v
dlouhých řadách , vyplnění extrémních formulářů a
odmítnutí úvěrových rozhodnutí založených na úvěrových skóre .
Nyní můžete svou hypotéku zaplatit rychle a efektivně v České republice. https://groups.google.com/g/sheasjkdcdjksaksda/c/EoSy1gqIwUI
Very interesting details you have mentioned, appreciate it for putting up.
Mom is the authority, and she is demonstrating
it nowadays by expressing us how to do it in the apartment!
In our Hot Daughter Porn film category, watch out for some
hot MILF pornstars and amateur women. By the time we’ve
finished with you, you’ll get imploring for Mommy because this XXX librarian has taken the Oedipus advanced to a whole new level!
Did you finish your chores already? This set is full of darling play and horny Stepmoms. http://www.americanstylefridgefreezer.co.uk/go.php?url=https://eugosto.pt/author/kjflavina18/
Thank you for sharing superb informations. Your website is very cool. I’m impressed by the details that you?¦ve on this site. It reveals how nicely you perceive this subject. Bookmarked this web page, will come back for more articles. You, my friend, ROCK! I found just the info I already searched everywhere and just could not come across. What an ideal web site.
excellent post.Never knew this, thankyou for letting me know.
Hi my friend! I want to say that this post is amazing, nice written and include approximately all significant infos. I¦d like to peer more posts like this .
Thanks for the auspicious writeup. It actually used to be a leisure account it. Glance advanced to far introduced agreeable from you! By the way, how could we be in contact?
Hello there, just became aware of your blog through Google, and found that it’s really informative. I am gonna watch out for brussels. I’ll be grateful if you continue this in future. A lot of people will be benefited from your writing. Cheers!